Bluetooth Tracking Project
In an earlier article I wrote about some of the ways Bluetooth technology can be used for building sensing and automation. This is an update to that post describing in more detail the architecture and some of the technology created along the way.
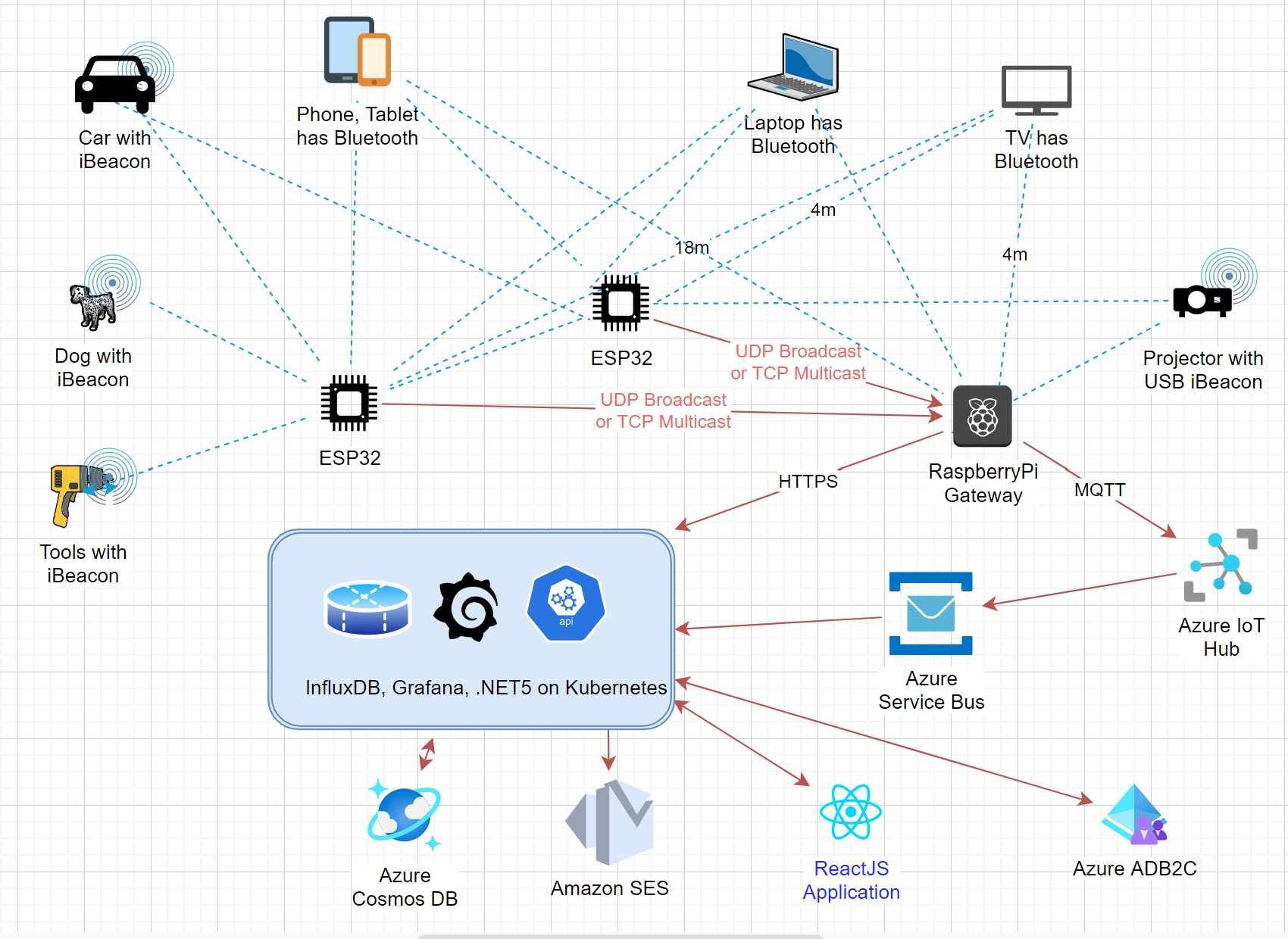
Architecture diagram
I tried to keep it simple, I really did, but it kept growing. Amazingly this whole system runs for a handful of dollars per month (I already had a Kubernetes cluster in Azure) and offers near infinite scalability. It's been a great learning experience and if anyone out there wants to license the world's finest dog, tool and person tracking system, call me!
Bluetooth devices
The system can track any Bluetooth equipped device that's sending advertisement packets. This includes phones, tablets, laptops, headphones, pens, and a whole host of wearables like fitness watches, and heartrate monitors. I've even seen Pokemon Go and Disney wristbands in the logs. It also picks up many fixed devices like TVs, and printers (which are great for calibrating the system as they don't move). Any other device can be turned into a tracked-device either by sticking a Bluetooth beacon on it or plugging in a USB iBeacon. The latter is only active when power is on, but that also gives you a way to track how many hours it runs for each day.
I've taken the system on the road a few times to test it. Costco was a good stress test, especially in the TV section. It's found many interesting devices on its travels including: (i) other cars, mostly Tesla and GM; (ii) garden sprinkler systems; (iii) a device that intercepts the throttle signal in a car to manage fuel efficient driving (yikes!); (iv) an industrial voltage and current meter; and most unusual of all (v) a device that is set in concrete to report the temperature as it dries!
I try to keep the logs anonymous and short-lived, but if you turn up at Starbucks with the same Bluetooth speaker named "Karen's Kitchen Speakers" every day, I can't help but notice. A full privacy review would be necessary before anyone deploys this system!
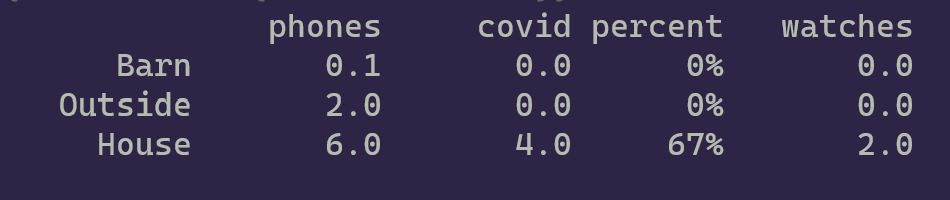
More recently the system has started finding phones running the Covid Trace application and my system can report on how many people are running it.
Nodes (ESP32 and Raspberry Pi)
The scanning software runs on an ESP32 or Raspberry Pi or on any Linux device with BlueZ. It's written in C and has minimal dependencies. The nodes all communicate to one Raspberry Pi nominated as a gateway. At the moment this is a static assignment but I'd like to move to a distributed consensus protocol like RAFT and have more fault-tolerance.
Nodes detect bluetooth devices in range and report their signal strength back to the gateway. They also attempt to discern more information about the device by examining name, mac address, GATT UUIDs, manufacturer data, ... Once one device has found the necessary information it communicates it to the others. Raspberry Pis are capable of finding out more information than ESP32s currently so a mixture of both is good.
Bluetooth has a suprisingly good range outside the building too and through something akin to trilateration the system can track people and devices even when they are outside. This is very useful for determining when someone has left a space.
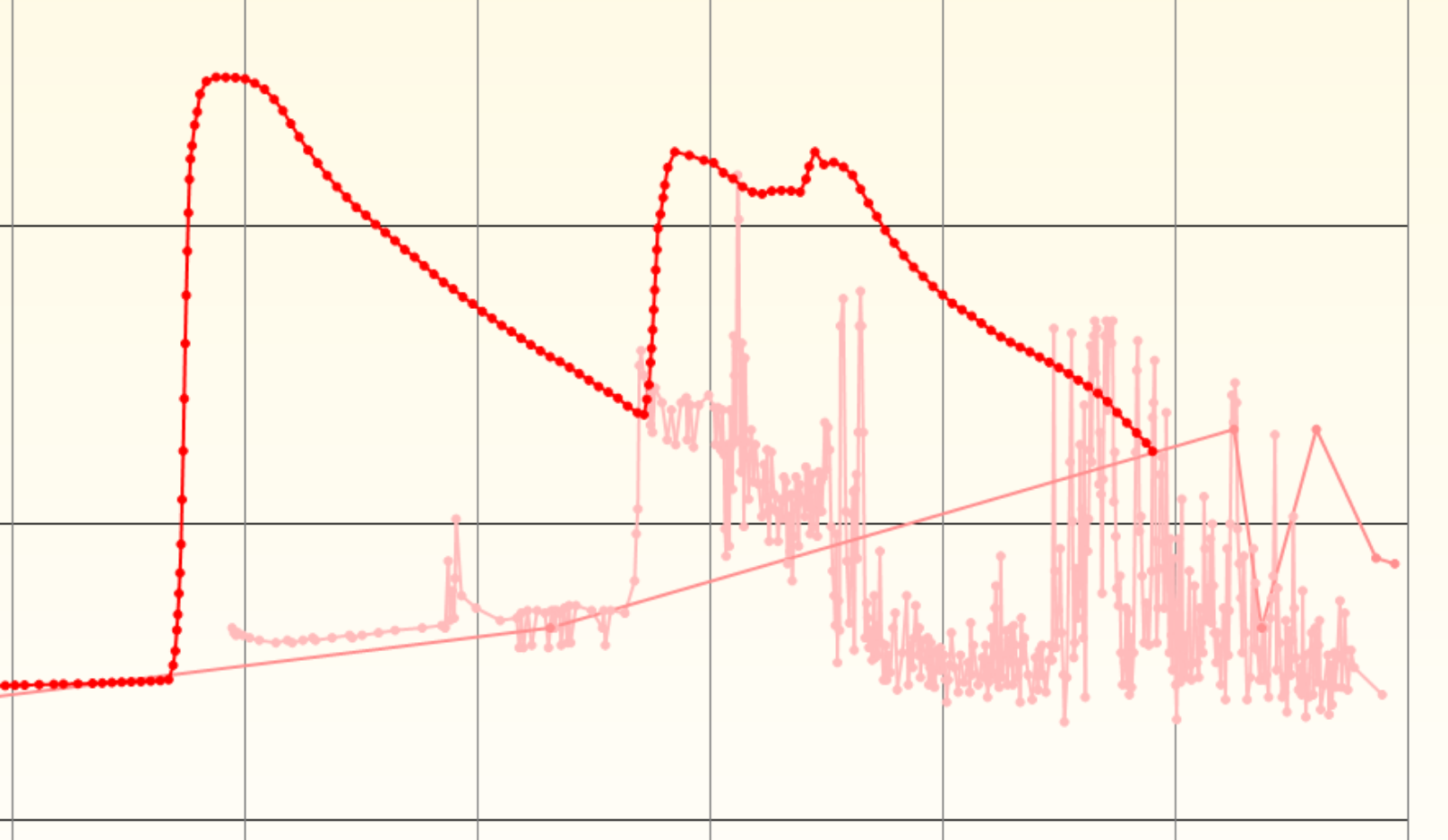
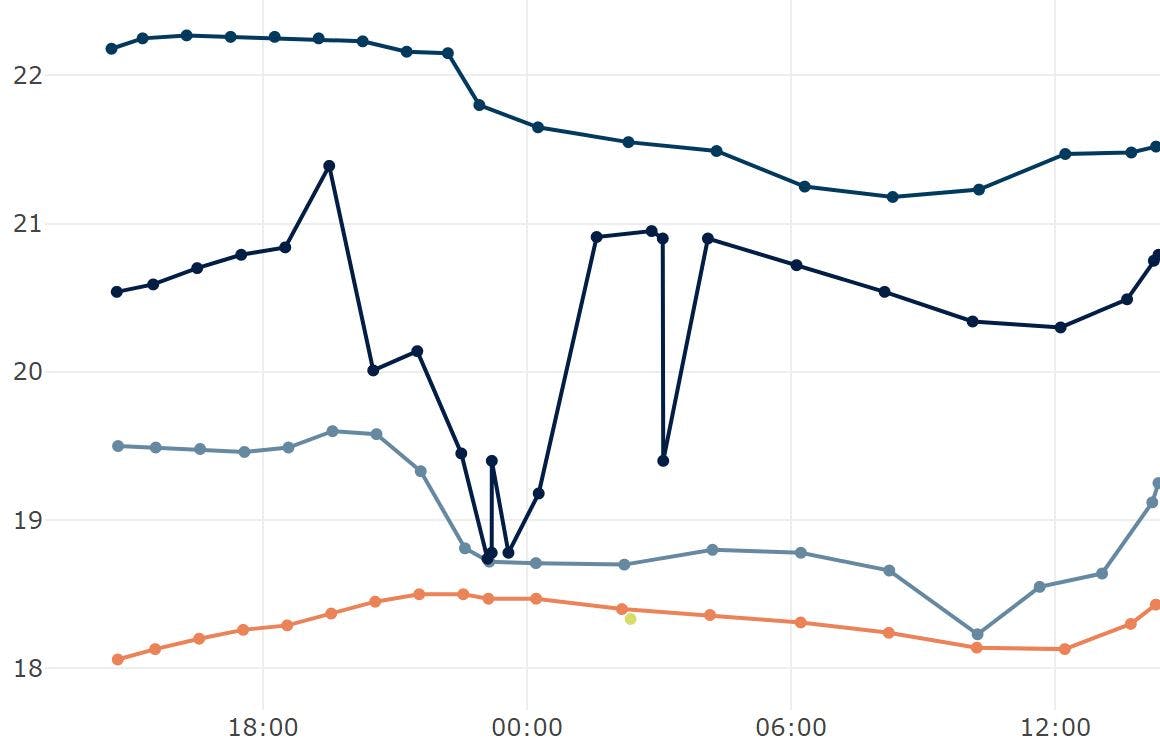
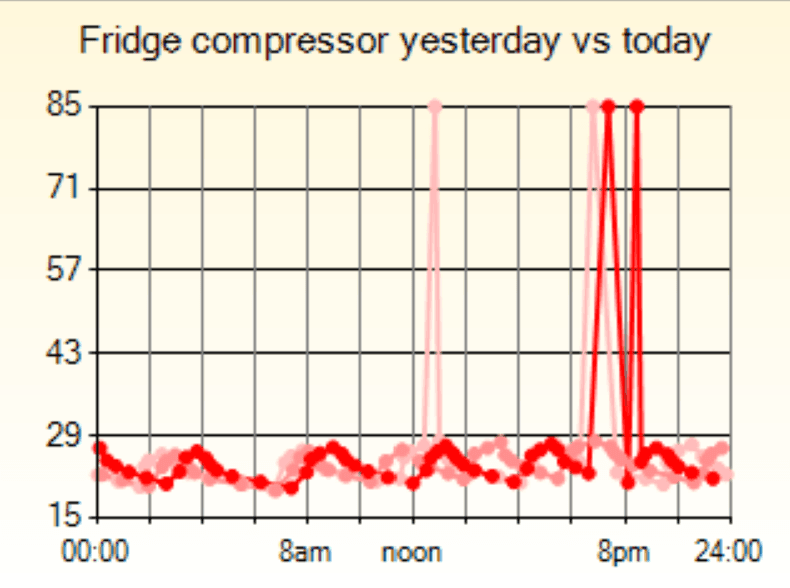
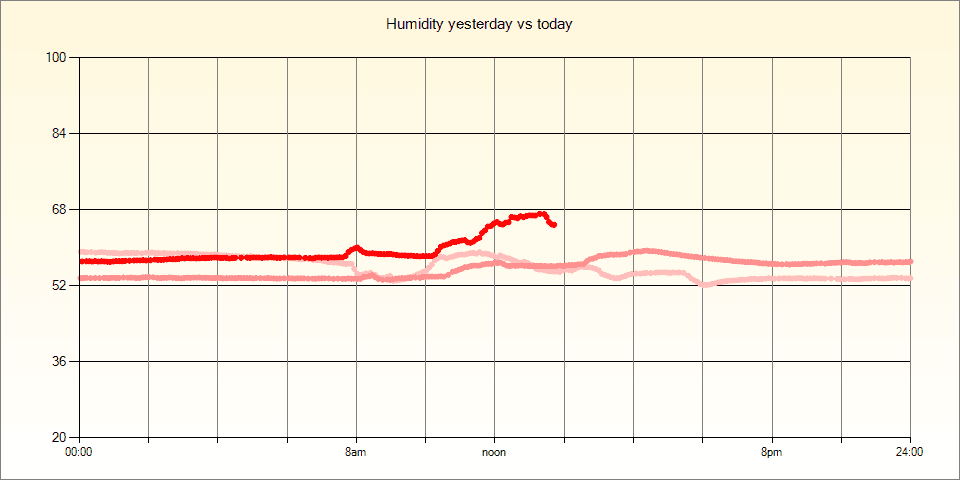
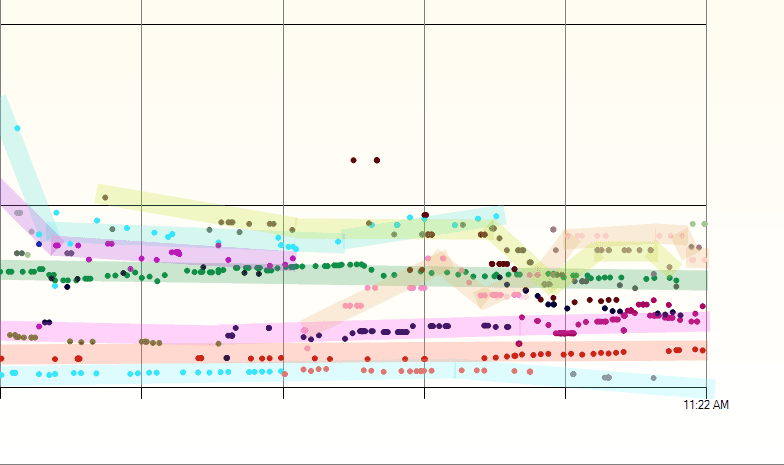
As an added bonus, since I have multiple nodes around the building I decided to connect other sensors to them. Most nodes now have a DHT22 or a BME680 and some have a microwave doppler radar board. Some of the nodes and sensors are in a 3D-printed enclosure that plugs into an outlet. The sensor data is typically passed through a Kalman filter to smooth out any noise. You can see the effect of the Kalman filter on a very noisy DHT22 in the chart above.
Each node runs a watchdog timer that reboots if it isn't responding correctly and the Raspberry Pi are all set to reboot at 3AM in their local timezone. There were also many steps to the process of hardening the Raspberry Pi to make sure they don't run out of disk space. For deployment to the Raspberry Pi I use SaltStack which has been a great experience. I can update a dozen Raspberry Pi as far away as Kuwait with one command - although I'm usually a lot more cautious and roll deployments slowly from local devices to far off devices with testing in between.
Gateway
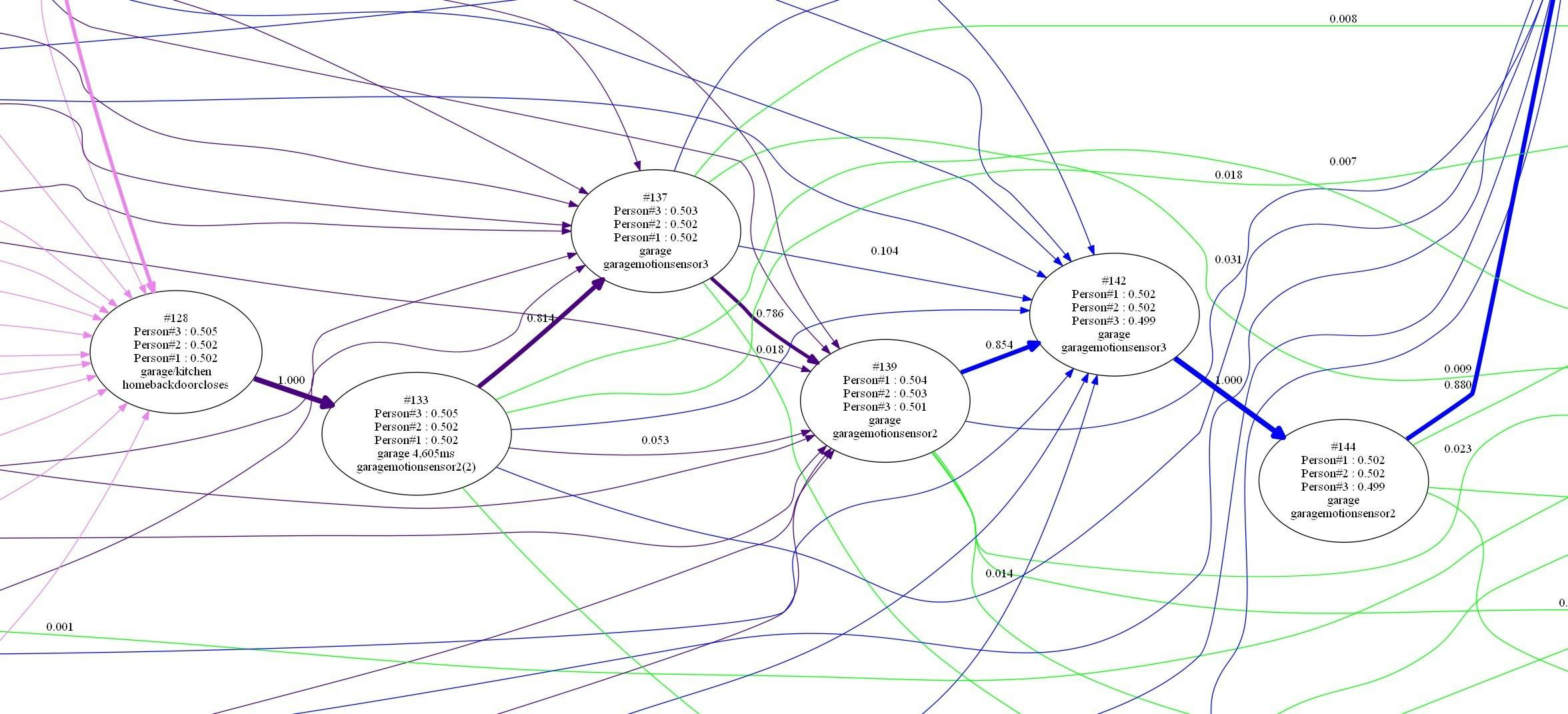
The gateway device is a Raspberry Pi 4. It receives information from all the other nodes in the system and can act as a node itself. From all the received signal strengths and device information it creates a list, 'repairing' the damage that MAC address randomization has done, with a consistent track for each device moving though the space.
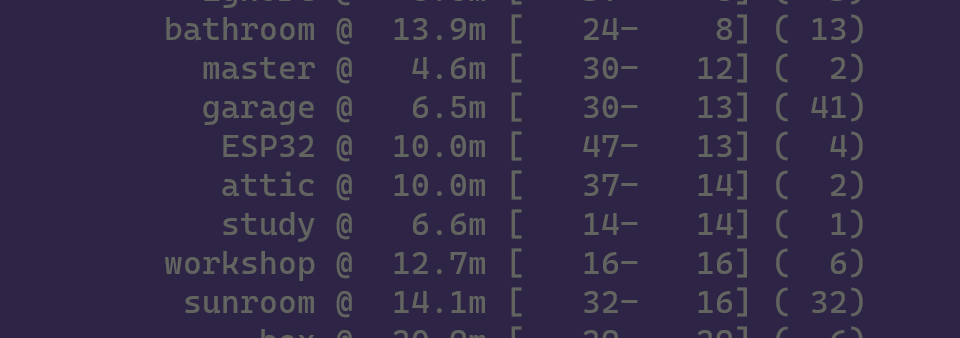
The gateway then compares the signal strengths (distances) received for any device with a database of known locations and signal strengths. The database can sometimes use just a single point per room, but may need more to handle variation in signal strengths caused by humidity, obstacles, ... this database is currently distributed to the nodes using Saltstack but I intend to move it to the return message channel from Azure IoT Hub.
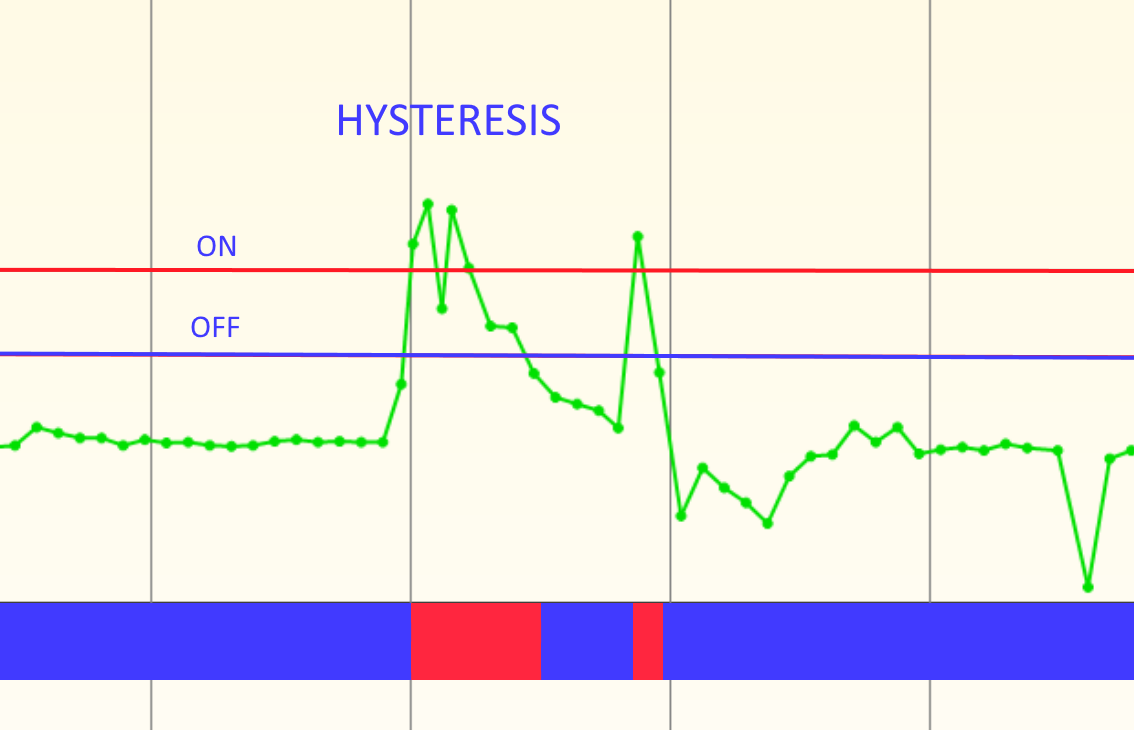
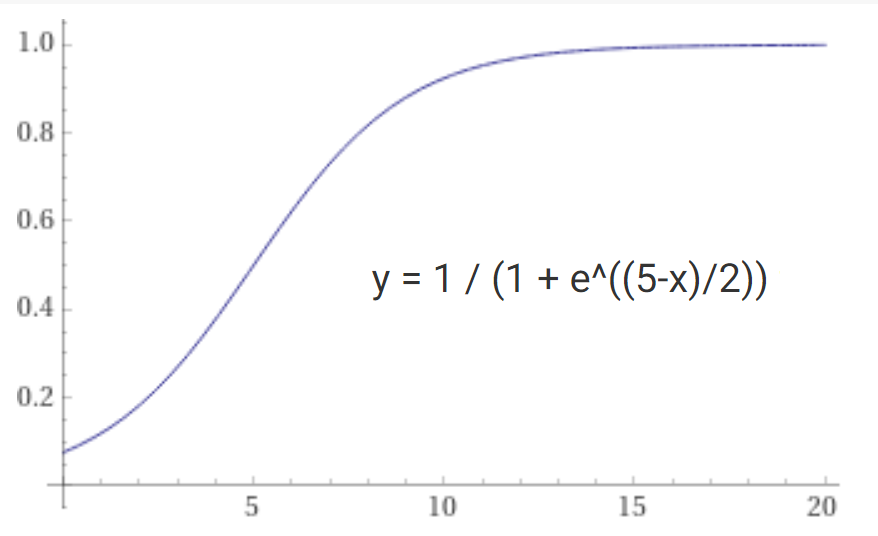
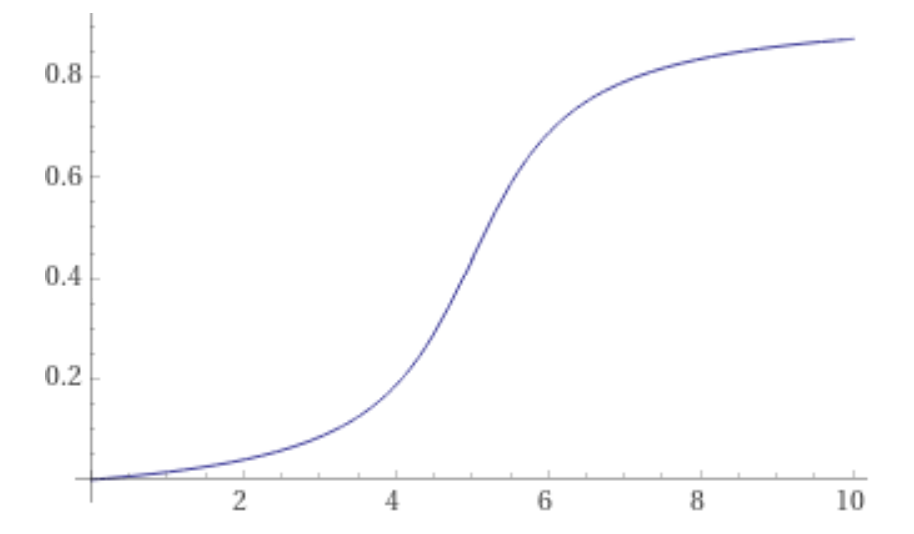
Early on I tried to build a classifier using Tensorflow. I also use the wonderful online ML service BigML) to explore some of the data. But I also hand-built a probability model that uses a sigmoid function applied to each distance delta and then some bayesian probability calculations over those. In practice it gave the best performance because it could handle missing distance observations (a common occurrence) and did not require much training data, as little as one example in many cases. It also operates quickly on even a low-power Raspberry Pi. It works surprisingly well, and over time I've tuned it to work even better. With a better understanding of the domain I may go back and try Tensorflow again and look into clustering algorithms that can find rooms without having to be told about them!

Once it's completed its local analysis of the data, has calculated how many people are in each room, and where each known asset (beacon) is located, it sends that information over MQTT to Azure IoT Hub and optionally to any local MQTT gateway.
The Gateway itself runs as two separate SYSTEMD services communicating over DBUS. The code is all pure C with minimal dependencies: just GLIB and BLUEZ for the receiving side and just GLIB and Azure IoT for the sending side. The Azure IoT code was a struggle, made more complex by having to understand CMAKE files and loads of options for what to compile. In the end because I didn't want to spend too much time on it I created my own MAKE file that compiles just the bits I needed into a lib. When I have time I'll go back and learn CMAKE, though it would be all round easier if Microsoft just published APT packages for Azure IoT that could be consumed on Raspberry Pi and Ubuntu.
For the DBUS Interface I use generated code: a simple XML file defines the notifications and API calls. The exposed DBUS API also enables the Gateway to act as a webserver through a small CGI script. This makes it very easy for other devices on the local network to display information, i.e. the original Crowd Alert concept.
It was hard to find great BlueZ examples online that handled edge cases and correctly released all memory that they allocated. Bluetooth information is similarly sketchy and it's taken a considerable effort to collect heuristics to recognize most common devices that pass by the system on a daily basis. I now have a fairly good database mapping Apple manufacturer data to iPhone vs iPad vs Macbook Pro. I'm still trying to track down device type 0x13 which I think is the new M1 Macbook Air.
Unfortunately the BlueZ stack on Raspberry Pi also filters Bluetooth Advertisement messages quite heavily. Since they are repeated frequently they make it eventually, but the ESP32 sees far more of them.
I had some issues with GLIB's Hashset implementation and in the end dropped using it and instead run my own linked list structures for all data. Some structures I know will never be disposed, but for the ones that do I'm careful to free everything and I run under VALGRIND all the time while testing. I did start down the Rust path at one point but came back to C fairly quickly: it's a steep learning curve. Once you have a few patterns down it's actually fairly easy to write correct code that doesn't leak memory (yes, I'm sure many have said the same thing before and been proven wrong too, but for now it's working well).
Azure IoT Hub
Azure IoT hub is a great way to collect all the telemetry data from the gateway devices. I also have all the nodes sending status back to Azure IoT Hub directly but might let them defer to their local gateway as a proxy in the future. Azure IoT hub gets me out of the business of creating a massively scalable, worldwide data ingress pipeline. Azure IoT Hub sends the data on to Azure Event Grid and Azure Service Bus. I've connected to both at the moment for testing. Azure Event Grid appears to have more information about connect and disconnect events. There's a good comparison of the two systems here.
Devices are provisioned from the .NET5 backend application calling into the Azure IoT Hub API. At the moment this relies on a secret in the SD-card image for the Raspberry Pi but in the future I'd like to use a TPM to make this more secure. Once a device has been added it receives a unique key which protects all future messages to Azure IoT Hub.
I don't use Azure Digital Twins currently, I may take another look later but for now my own database schema and my own graph database provide similar capabilities and Azure Digital Twins are still evolving rapidly. I also think that the perfect digital twin will ultimately involve many extra capabilities that I've found necessary over the years.
.NET5 Ingress Application
The ingress application will eventually move to an Azure Function but for now it's part of the Web Application. It listens to Azure Event Grid and Azure Service Bus and dumps all data received into Azure Cosmos Database using the MongoDB API. Each message includes information about how many people are in each room, how recently each gateway or node was seen, and any sensor data that has changed since the last communication.
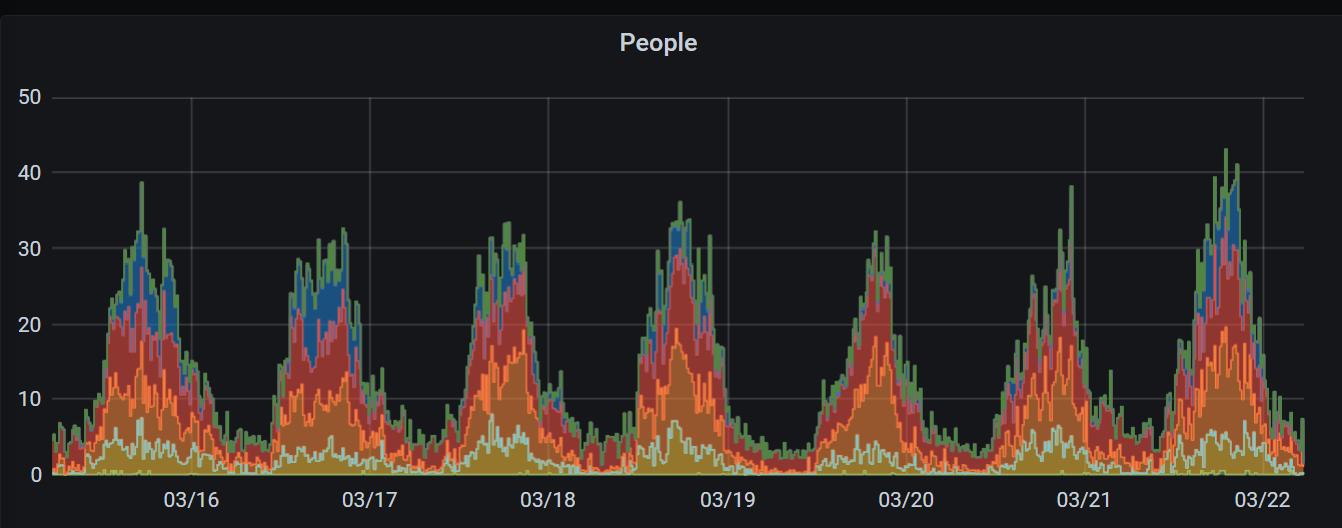
InfluxDB and Grafana
At the moment, gateway devices communicate directly to InfluxDB and all of the graphs and charts are viewable in Grafana. This is an entirely separate system and eventually would be removed in favor of the .NET5 / ReactJS web application. I may still use InfluxDB but I also have plenty of time-series database code for use with MongoDB. Influx and Grafana are running in the same Kubernetes cluster.
Web Application
The web application is written in .NET5 on the backend and ReactJS-functional with Typescript and Redux on the front end. I'm using Bootstrap and react-icons too. Not much novel here but I did develop my own ReactJS infinite grid component which allows for data to be added to either side of the current view without losing position (handy for viewing log-like scrolling pages of items whilst they are being written to on the server).
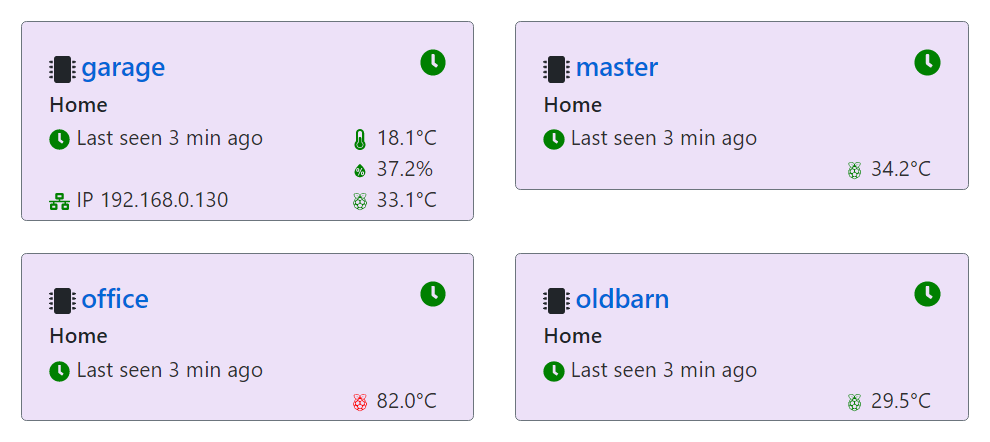
The web api is exposed as a Swagger endpoint and NSwagStudio runs to create a Typescript client. I use Luxon for DateTimes.
I typically use Autofac for dependency injection and Serilog for logging but for this application I tried to go pure Microsoft.Extensions. I did however stick with Newtonsoft JSON so I didn't have to remember all the ways System.Text.Json breaks down.
Authentication
Azure ADB2C provides the authentication system, user information is stored only in Azure Active Directory and currently three forms of login are supported: username/password, Facebook or Google. Ironically I was not able to get the Microsoft Login to work well with Azure ADB2C and gave up to focus on other things. Azure ADB2C with the React authentication component (MSAL) wasn't particualrly fun to get working and I need to do another pass over it to clean up a bit, but it works for now.
Graph Database
I've been a proponent of graph databases for many years and I was hoping to use the new Gremlin Support for Azure Cosmos but there's a number of features it doesn't support yet, so for now I'm sticking with my own graph implementation which runs on MongoDB. Using an RDF-triple-store-like schema with a single collection for all entities and a single collection for 'statements' (Subject-Predicate-Object) allows me to very rapidly prototype new features. I have a 'classless' serializer which serializes and deserializes using interfaces not classes and you can even dynamically morph an object to add a new interface at run time! Yes, duck-typing in .NET using Impromptu Interface. Yes, it will never scale to billions of users, but for now it allows very rapid development. Without changing any data layer code I can add a new type (just add the interface) and I can easily add new relationships between types (just add triples to the statement store). And since it's a graph database I can also do traversals to find, say, all the sensors on a given floor, or all the devices that are wired to a given other device. The graph database can model physical, electrical and other connections seamlessly, and new concepts can be added easily. Because it's an RDF-like graph I can even use nodes as edges and reason about nodes at a higher-level using the same graph, a meta-graph if you like.
After loading a portion of the graph from MongoDB (Cosmos) it can be manipulated in memory using my own .NET Graph Library. This library matches the capabilities of the graph database and uses the same RDF-triple-like model, but it also handles traversals like page rank and topological sort.
Currently the graphs for my test sites are defined in code but I will probably move the definitions to RDF/TTL or YAML.
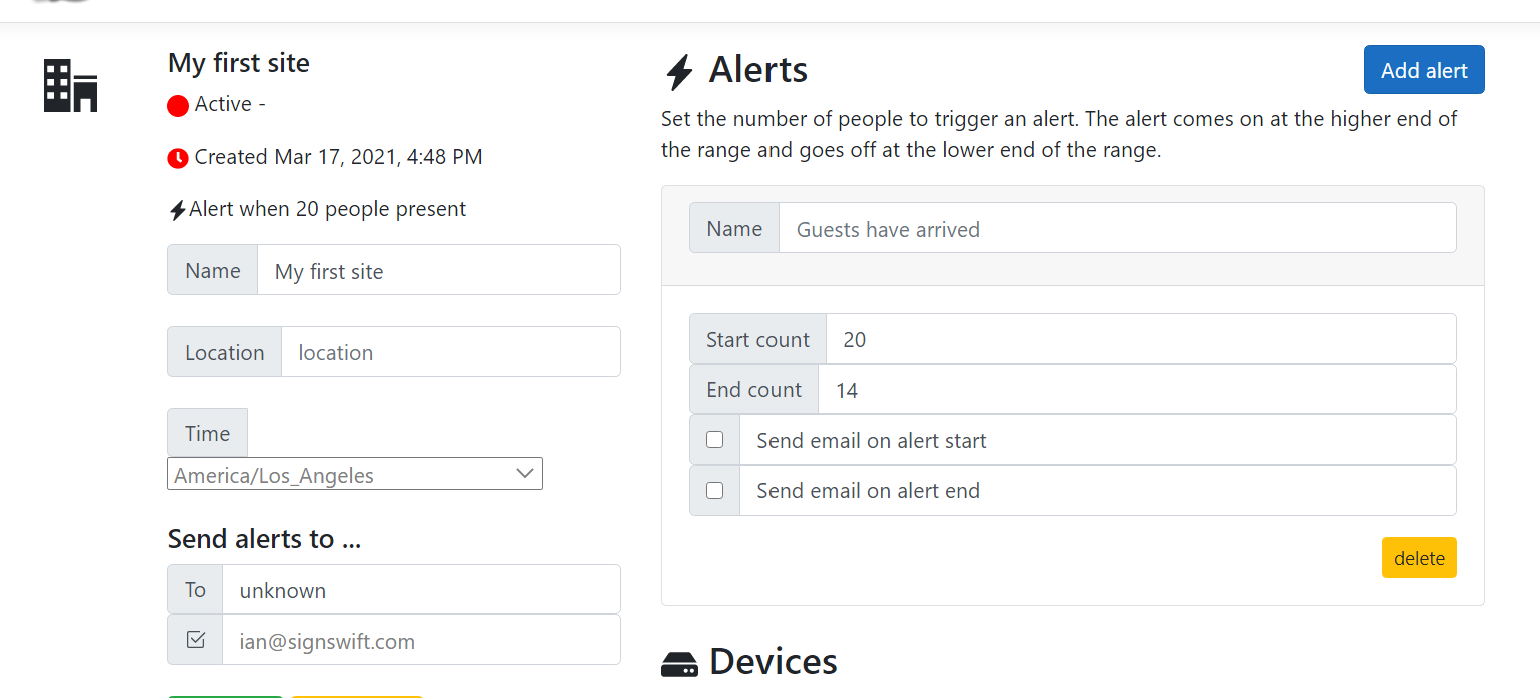
Email Alerts
I'm currently using Amazon SES for all email delivery for password reset, email verification and email alerts. I happen to have one already set up on my domain and the effort of setting up another and getting all the MX records right so that mail arrives without spam filters rejecting it was too much effort for now.
DNS and TLS Certificates
I use Amazon Route 53 for all DNS records. TLS (SSL) certificates which used to be a huge pain point are now a piece of cake using cert-manager on Kubernetes which renews Let's Encrypt certificates completely automatically. I can even add a new site on a new domain and during the deployment process it gets a new ceritificate with no effort on my part. No more CSR, CRT, PEM, PK7, OpenSSL, ... nonsense.
The entire Kubernetes YAML file is around 100 lines long to install the app, connect it through NGINX, offload SSL and to handle certificate renewal. I had hoped to run my app on Azure's managed pay-as-you-go Kubernetes service but it had so many limitations I ended up spinning up my own, small (single node) cluster.
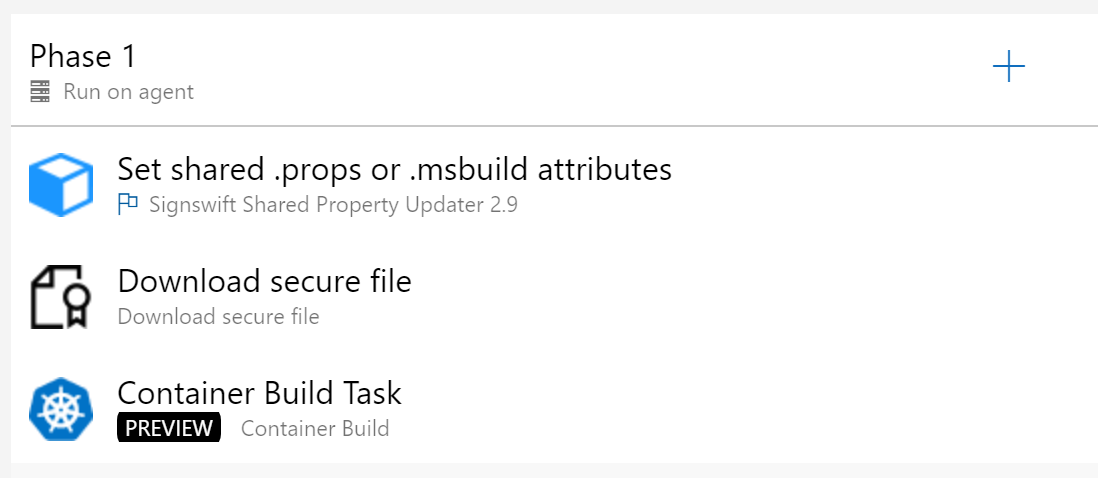
Build Pipeline (Azure DevOps)
The source code is in GitHub and the build runs on Azure Dev Ops. It's just three steps because most of the build instructions are in the Dockerfile (itself only 36 lines long). Being able to build and run the exact same configuration locally for testing is great too; I've even deployed some of my sites to a Raspberry Pi running docker and they worked identically when deployed to Azure.
The first build step is a custom build step that I really should get around to publishing: it versions assemblies by updating a shared.msbuild file. It's based on an existing one that attempted to update CSPROJ and assemblyinfo files but it's really so much cleaner to move all that into a shared file and version it once.
I run my own build agent because my hexa-core M.2 SSD desktop is faster than Azure build agents and because it can cache data between builds. I also run Docker here for all image builds rather than on my laptop. Publishing the image back to Azure Container Registry is a bit slower but the whole build process takes just 2m 4s and deployment takes just 17s (excluding the time it takes Kubernetes to spin up the new pod and remove the old one).
Deployment
When a build completes successfully the Azure Release Pipeline immediately deploys it to a Kubernetes pod in a test namespace. It runs a few quality gates against that and if it passes those, it deletes the test namespace and updates the production namespace to the new image using kubectl apply and then kubectl rollout. Namespaces are incredibly important in Kubernetes and I wish I'd learned that sooner - they are the unit of deployment and deletion!
Logging
The Linux components log using GLIB's logging methods and I use journalctl to view the logs locally or remotely using Saltstack. journalctl is a wonderful piece of code and coupled with grep (sometimes more than once, often with -A or -B to get lines either side) and cut, it's very easy to find the logs I need to view. I wish Windows had something like this instead of EventViewer!
Summary
I've used many of the components mentioned here in previous consulting positions but this is the first time I've built an entire system end-to-end from low-level microcontroller code, through Linux systemd services, through Azure IoT, Cosmos and ultimately to the browser and ReactJS. It required reading upward of 100 blog posts and Stackoverflow questions and I filed at least ten bugs against Azure Portal, Azure documentation and Azure DevOps along the way, most of which are already fixed, some were fixed the same day I reported them!
If you don't already have a personal project where you can learn new stuff, I highly recommend you start one. Software has changed so much over the past few years and we all need to keep learning. I attempted here to start with the latest, greatest technology in each layer of the stack, but by this time next year, half of it will need updating to be current!
Also, if anyone needs an almost-complete person, sensor, asset and dog tracking system designed to scale to millions of buildings, devices and pets please call me!
![]()