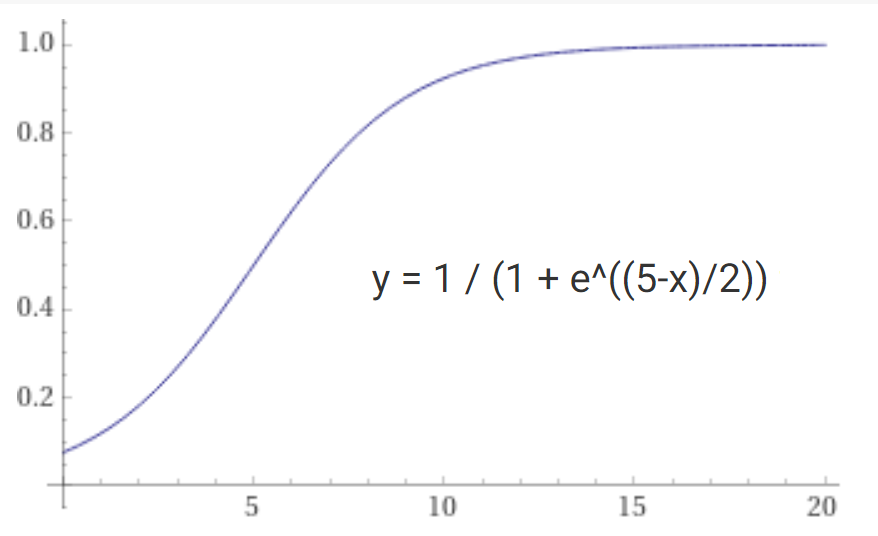
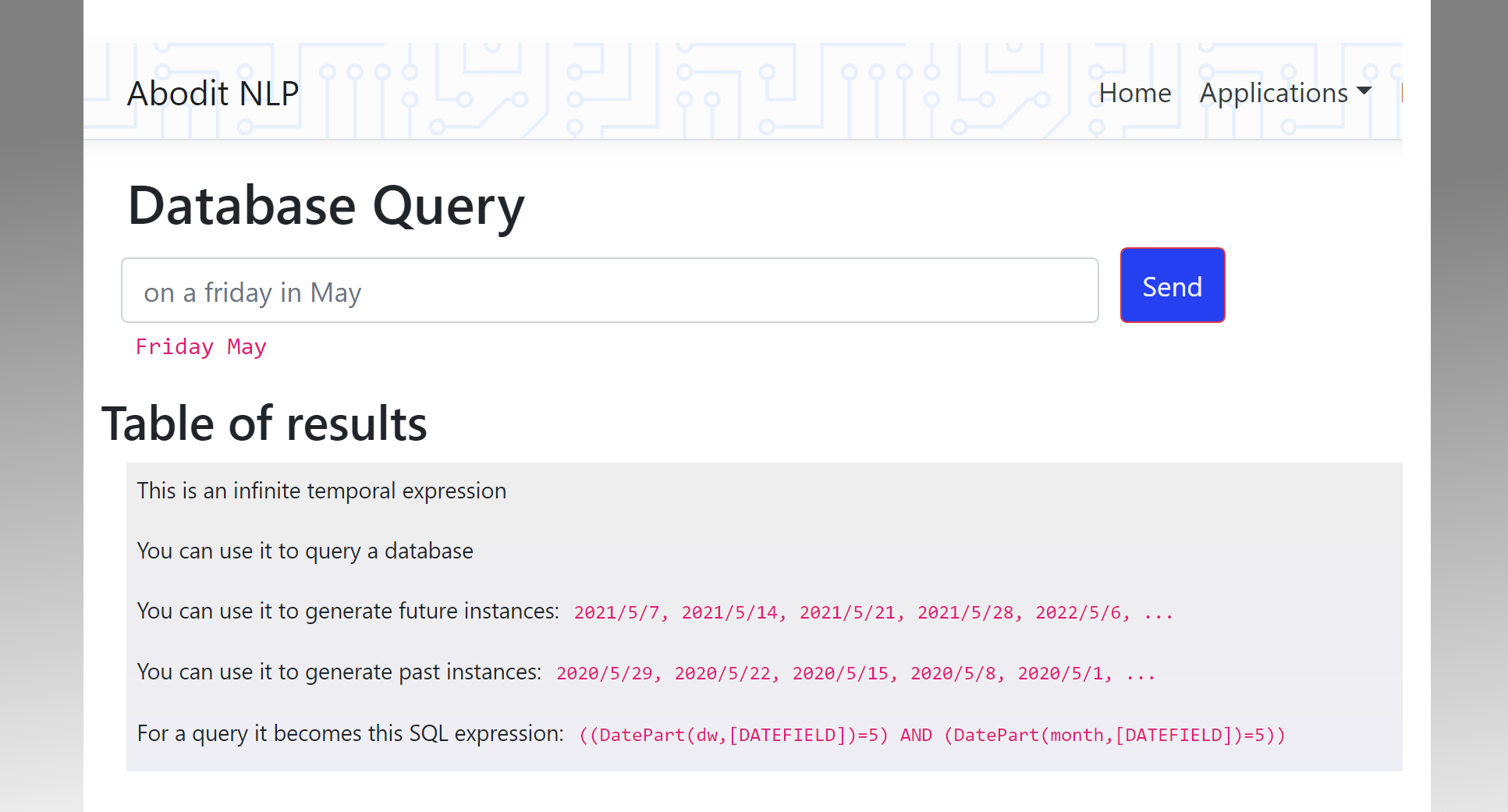
Algorithm Complexity and the 'Which one will be faster?' question
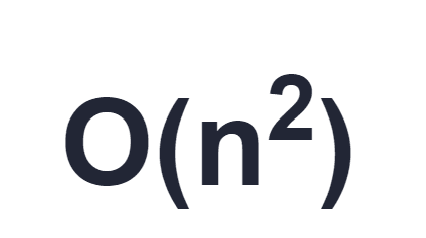
Over and over on Stackoverflow.com people ask a question of the form 'If I have an algorithm of complexity A, e.g. O(n.log(n)), and an algorithm of complexity B, which one will be faster?' Developers obsess over using the cleverest algorithm available with the lowest theoretical bound on complexity thinking that they will make their code run faster by doing so. To many developers the simple array scan is anathema, they think they should always use a SortedCollection with binary search, or some heap or tree that can lower the complexity from O(n squared) to O(n.log(n)).
To all these developers I say "You cannot use the complexity of an algorithm to tell you which algorithm is fastest on typical data sets on modern CPUs".
I make that statement from bitter experience having found and implemented a search that could search vast quantities of data in a time proportional to the size of the key being used to search and not to the size of the data being searched. This clever suffix-tree approach to searching was beaten by a simple dumb array scan! How did that happen?
First you need to understand that there are constants involved. An algorithm might be O(n) but the actual instruction execution time for each step might be A microseconds. Another algorithm of O(n.log(n)) might take B microseconds to execute each step. If B >> A then for many values of n the first algorithm will be faster. Each algorithm may also involve a certain set up time and that too can dwarf execution time when n is small.
But here's the catch: even if you think the number of add and multiply instructions between the two algorithms is similar, the CPU you are executing them on may have a very different point of view because modern x86 CPUs have in effect been optimized for dumb programmers. They are incredibly fast at processing sequential memory locations in tight loops that can fit in on-chip RAM. Give them a much more complex tree-based O(n log(n)) algorithm and they now have to go off-chip and access scattered memory locations. The results are sometimes quite surprising and can quickly push that O(n log(n)) algorithm out of contention for values of n less than several million.
For most practical algorithms running on typical datasets the only way to be sure that algorithm A is faster than algorithm B is to profile it.
The other huge catch is that even when you have profiled it and found that your complex algorithm is faster, that's not the end of the story. Modern CPUs are now so fast that memory bottlenecks are often the real problem. If your clever algorithm uses more memory bandwidth than the dumb algorithm it may well affect other threads running on the same CPU. If it consumes so much memory that paging comes into play then any advantage it had in CPU cycles has evaporated entirely.
An example I saw once involved someone trying to save some CPU cycles by storing the result in a private member variable. Adding that member variable made the class larger and as a result less copies of it (and all other classes) could fit in memory and as a result the application overall ran slower. Sure the developer could claim that his method was now 50% faster than before but the net effect was a deterioration in the overall system performance.