A Semantic Web ontology / triple Store built on MongoDB
In a previous blog post I discussed building a Semantic Triple Store using SQL Server. That approach works fine but I'm struck by how many joins are needed to get any results from the data and as I look to storing much larger ontologies containing billions of triples there are many potential scalability issues with this approach. So over the past few evenings I decided to try a different approach and so I created a semantic store based on MongoDB. In the MongoDB version of my semantic store I take a different approach to storing the basic building blocks of semantic knowledge representation. For starters I decided that typical ABox and TBox knowledge has really quite different storage requirements and that smashing all the complex TBox assertions into simple triples and stringing them together with meta fields only to immediately join then back up whenever needed just seemed like a bad idea from the NOSQL / document-database perspective.
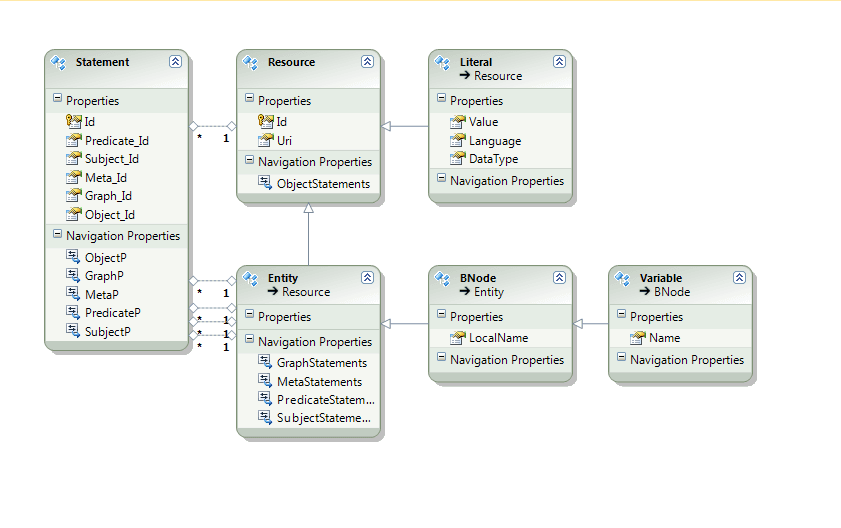
TBox/ABox: In the ABox you typically find simple triples of the form X-predicate-Y. These store simple assertions about individuals and classes. In the TBox you typically find complex sequents, that's to say complex logic statements having a head (or consequent) and a body (or antecedents). The head is 'entailed' by the body, which means that if you can satisfy all of the body statements then the head is true. In a traditional store all the ABox assertions can be represented as triples and all the complex TBox assertions use quads with a meta field that is used solely to rebuild the sequent with a head and a body. The ABox/TBox distinction is however arbitrary (see http://www.semanticoverflow.com/questions/1107/why-is-it-necessary-to-split-reasoning-into-t-box-and-a-box).
I also decided that I wanted to be use ObjectIds as the primary way of referring to any Entity in the store. Using the full Uri for every Entity is of course possible and MongoDB couuld have used that as the index but I wanted to make this efficient and easily shardable across multiple MongoDB servers. The MongoDB ObjectID is ideal for that purpose and will make queries and indexing more efficient.
The first step then was to create a collection that would hold Entities and would permit the mapping from Uri to ObjectId. That was easy: an Entity type inheriting from a Resource type produces a simple document like the one shown below. An index on Uri with a unique condition ensures that it's easy to look up any Entity by Uri and that there can only ever be one mapping to an Id for any Uri.
RESOURCES COLLECTION - SAMPLE DOCUMENT
{
"_id": "4d243af69b1f26166cb7606b",
"_t": "Entity",
"Uri": "http://www.w3.org/1999/02/22-rdf-syntax-ns\#first"
}
Although I should use a proper Uri for every Entity I also decided to allow arbitrary strings to be used here so if you are building a simple ontology that never needs to go beyond the bounds of this one system you can forgo namespaces and http:// prefixes and just put a string there, e.g. "SELLS". Since every Entity reference is immediately mapped to an Id and that Id is used throughout the rest of the system it really doesn't matter much.
The next step was to represent simple ABox assertions. Rather than storing each assertion as its own document I created a document that could hold several assertions all related to the same subject. Of course, if there are too many assertions you'll still need to split them up into separate documents but that's easy to do. This move was mainly a convenience for developing the system as it makes it easy to look at all the assertions made concerning a single Entity using MongoVue or the Mongo command line interface but I'm hoping it will also help performance as typical access patterns need to bring in all of the statements concerning a given Entity.
Where a statement requires a literal the literal is stored directly in the document and since literals don't have Uris there is no entry in the resources collection.
To make searches for statements easy and fast I added an array field "SPO" which stores the set of all Ids mentioned anywhere in any of the statements in the document. This array is indexed in MongoDB using the array indexing feature which makes it very efficient to find and fetch every document that mentions a particular Entity. If the Entity only ever appears in the subject position in statements that search will result in possibly just one document coming back which contains all of the assertions about that Entity. For example:
STATEMENTGROUPS COLLECTION - SAMPLE DOCUMENT
{
"\id": "4d243af99b1f26166cb760c6",
"SPO": [ "4d243af69b1f26166cb7606f", "4d243af69b1f26166cb76079", "4d243af69b1f26166cb7607c" ],
"Statements": [
{
"_id": "4d243af99b1f26166cb760c5",
"Subject": { "_t": "Entity", "_id": "4d243af69b1f26166cb7606f", "Uri": "GROCERYSTORE" },
"Predicate": { "_t": "Entity", "_id": "4d243af69b1f26166cb7607c", "Uri": "SELLS" },
"Object": { "_t": "Entity", "_id": "4d243af69b1f26166cb76079", "Uri": "DAIRY" }
}
... more statements here ...
]
}
The third and final collection I created is used to store TBox sequents consisting of a head (consequent) and a body (antecedents). Once again I added an array which indexes all of the Entities mentioned anywhere in any of the statements used in the sequent. Below that I have an array of Antecedent statements and then a single Consequent statement. Although the statements don't really need the full serialized version of an Entity (all they need is the _id) I include the Uri and type for each Entity for now. Variables also have Id values but unlike Entities, variables are not stored in the Resources collection, they exist only in the Rule collection as part of consequent statements. Variables have no meaning outside a consequent unless they are bound to some other value.
RULE COLLECTION - SAMPLE DOCUMENT
{
"_id": "4d243af99b1f26166cb76102",
"References": [ "4d243af69b1f26166cb7607d", "4d243af99b1f26166cb760f8", "4d243af99b1f26166cb760fa", "4d243af99b1f26166cb760fc", "4d243af99b1f26166cb760fe" ],
"Antecedents": [
{
"_id": "4d243af99b1f26166cb760ff",
"Subject": { "_t": "Variable", "_id": "4d243af99b1f26166cb760f8", "Uri": "V3-Subclass8" },
"Predicate": { "_t": "Entity", "_id": "4d243af69b1f26166cb7607d", "Uri": "rdfs:subClassOf" },
"Object": { "_t": "Variable", "_id": "4d243af99b1f26166cb760fa", "Uri": "V3-Class9" }
},
{
"_id": "4d243af99b1f26166cb76100",
"Subject": { "_t": "Variable", "_id": "4d243af99b1f26166cb760fa", "Uri": "V3-Class9" },
"Predicate": { "_t": "Variable", "_id": "4d243af99b1f26166cb760fc", "Uri": "V3-Predicate10" },
"Object": { "_t": "Variable", "_id": "4d243af99b1f26166cb760fe", "Uri": "V3-Something11" }
}],
"Consequent":
{
"_id": "4d243af99b1f26166cb76101",
"Subject": { "_t": "Variable", "_id": "4d243af99b1f26166cb760f8", "Uri": "V3-Subclass8" },
"Predicate": { "_t": "Variable", "_id": "4d243af99b1f26166cb760fc", "Uri": "V3-Predicate10" },
"Object": { "_t": "Variable", "_id": "4d243af99b1f26166cb760fe", "Uri": "V3-Something11" }
}
}
That is essentially the whole semantic store. I connected it up to a reasoner and have successfully run a few test cases against it. Next time I get a chance to experiment with this technology I plan to try loading a larger ontology and will rework the reasoner so that it can work directly against the database instead of taking in-memory copies of most queries that it performs.
At this point this is JUST AN EXPERIMENT but hopefully someone will find this blog entry useful. I hope later to connect this up to the home automation system so that it can begin reasoning across an ontology of the house and a set of ABox assertions about its current and past state.
Since I'm still relatively new to the semantic web I'd welcome feedback on this approach to storing ontologies in NOSQL databases from any experienced semanticists.