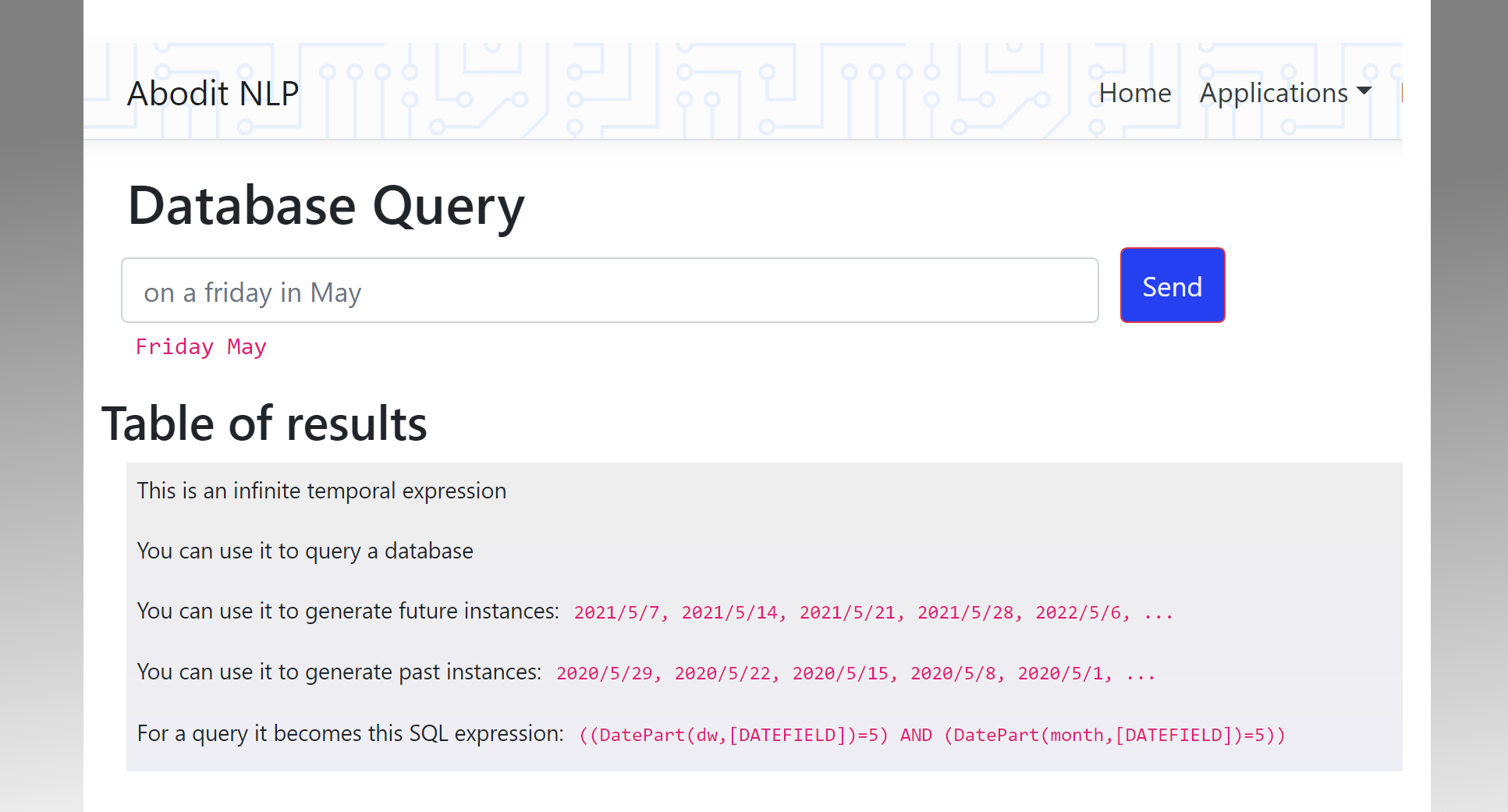
The future of user interface design is multi-modal and context aware
Current user interfaces are primarily limited to a single input device. We type on a keyboard, we point and drag with a mouse or we speak to an application that accepts only voice. Our computer doesn't know if we are sat in front of it, let alone whether we are talking to someone else or looking at something else. As a result computers appear stupid and rude. They are oblivious to our frantic mouse movements on screen 2 while we are looking at screen 1 wondering where the mouse pointer is hiding. They pop up messages and make noises even though we are busy with another task or in the middle of a conversation with someone else.
This will change. In the future computers will become more aware of their surroundings and of their users. They will track your eyes, they will listen constantly to what you are saying and what is going on in the room around them and they will begin to appear to be smarter and a whole lot less rude than they are today.
But I also think that UI will become multimodal. We will combine mouse movement with speech, computers will ask questions and learn. For example, I was just working on a repetitive edit on a block of code. In the future computers will ask, using a spoken voice, whether we want them to apply the same edit to the remainder of the lines in that block. And because the interaction is multi-modal it does not interrupt the flow of what you are doing. There is no pop-up message to distract you visually, there is no dismiss button you need to click to make Clippy go away. As humans we do fairly well at isolating different inputs (visual, verbal, auditory, tactile, ...) and can ignore one while we focus on another. Multi-modal UI will take advantage of that and will appear less intrusive and far less annoying than previous attempts at assistive technology.
But even without computerized assistants, multimodal UI will become common. You will be able to select a block of text and say "make it larger" without having to go find the right command in a dialog launched from a menu. As we move from desktops to tablets this capability becomes even more important because we have less screen real-estate and because typing and mousing are harder.
Multimodal UI also benefits from the combinatorial, multiplicative effect of different inputs. You only need one command "make it larger" rather than make paragraph larger, make image larger, make space between lines larger, make margin larger, ...
Multimodal UI also saves a lot of mouse movement and solves many of the issues around selections (e.g. do they go away when you select a menu item, or click on a different application).
Multimodal UI will also dramatically reduce how often you need to click: merely pointing at something and saying the command will be sufficient.
I strongly believe that this will be a key part of future user interfaces, but in the meantime, let me go dismiss this dialog asking if I want to reboot to install updates...