The 'Learning Database' or 'Why do we need so many different databases?'
It's 2011 and database management and design is still a tedious job. Software does more amazing things every day but when it comes to databases it's back to 1970 in many ways.
My ideal database would borrow from RDBMS (like SQL Server), Document databases (like MongoDB), Graph Databases and Semantic Web Triple Stores; it would be the perfect hybrid of all of these and it would configure itself to be as efficient as possible answering queries.
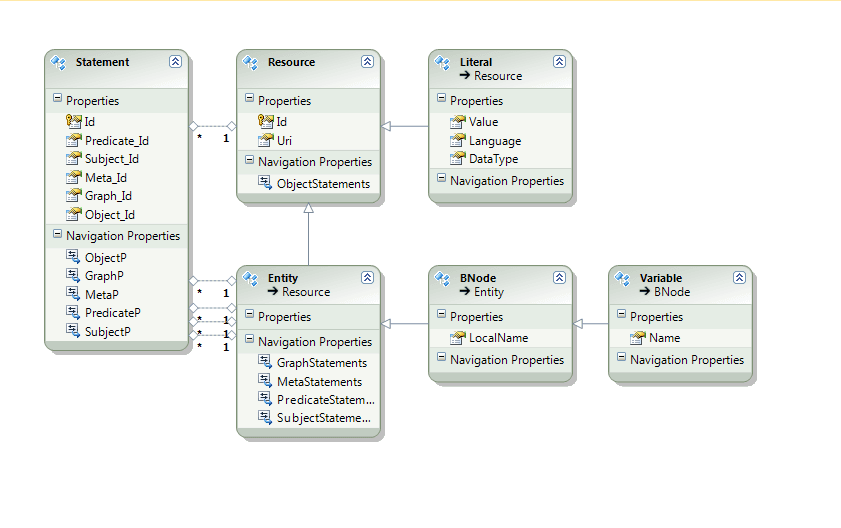
Initially it might start storing data using a triple store format (since that's one of the simplest forms of database and yet is capable of some of the richest expression of facts), it might use some graph database techniques to improve performance on the triple store. As triples accumulate regarding a specific subject (or object) it would automatically cluster them and use MongoDB-like documents to store the data in a way that can be retrieved efficiently (like I do in my MongoDB triple store). As more data piles up and the important columns become apparent it would switch some of the data to a relational database format and add any necessary indexes. All this would happen totally automatically.
It would of course also include map-reduce, using whatever language you want to use, and it would shard and replicate itself across servers automatically to maximize performance or reliability or whatever you want it to maximize. Advanced semantic reasoning capabilities would also be included so you can ask complex SPARQL queries expressing logic that you simply cannot do with relational databases today.
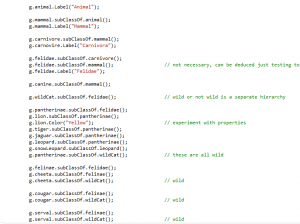
At this point the DBAs in the audience are freaking out, partly because they don't have a job any more, but also because they want to ask all the usual questions "what about constraints?", "what about foreign keys?", and of course "what about stored procedures?" because they can't live without that Cobol-esque T-SQL syntax. Well, guess what DBAs, OWL is a much more powerful way of expressing all those constraints. Using OWL and other semantic web technologies you can build complex ontologies that define how the data is represented and the constraints on it. You can even create an Ontology for your rules, and an Ontology for your Ontology for you rules, .... and so on.
I think this is where databases will end up, and I hope that CJ Date (one of the fathers of modern databases) will still be around to see it!