A Bayesian Spam / Relevance Filter for Seesmic / Twitter
Twitter is a great resource but it's just so full of noise that sometimes I question its value to me. In between the awesome information I get from it I have to wade through check-ins, mealtimes and childcare woes. I'm sorry but what you had for lunch really isn't that interesting to me unless it's some amazing new restaurant right near me.
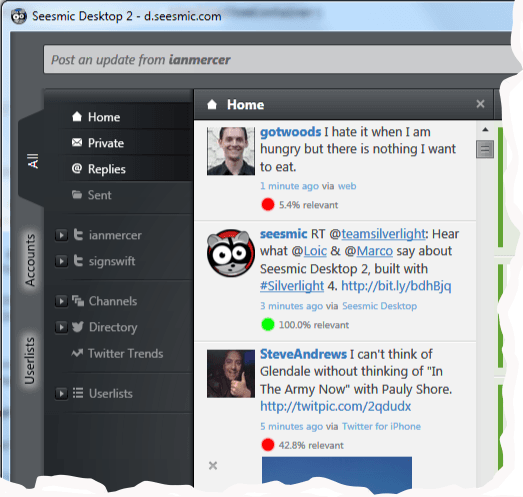
I wanted an easy way to see just the relevant bits so this weekend I knocked up a quick Seesmic plugin that uses a Bayesian filter to analyze each Tweet and score it for relevance. You can right click on any Tweet to say "Relevant" or "Not relevant" and it soon learns to categorize tweets using a red - green color dot and a score. There's a cut-off value too below which it simply hides the Tweet (but for the screen-shot I turned this off).
The Seesmic API was easy to learn (if somewhat lacking in documentation and complete working examples). The Visual Studio Templates provided by Tim Heuer came in handy too. The Managed Extensibility Framework made it very easy to write the plug-in - I just wish Seesmic could auto re-load it each time you drop a new version in there. Restarting Seesmic each time was annoying and caused Twitter to rate-limit me more than once.
Information about what you like and don't like is stored in IsolatedStorage in a simple flat file. The file is reloaded on startup and the probabilities for each word are recalculated.
If I get time and if there's sufficient interest I might take this a bit further but for now I'm happy to have less to read.
[Apologies to anyone who is red-dotted in the screen-shot, I'm sure you have lots of good Tweets too which is why I'm following you, I just happened upon this one which is noise to me.]