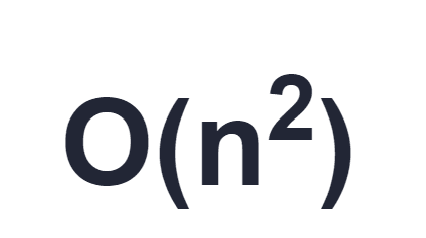Optimization Advice
Optimization is the root cause of much unmaintainable code. It is also the root cause of many bugs. My advice to the vast majority of programmers is to stay away from it: if you have a good architecture you should not need to optimize it at this level.
Personally I divide optimization into three buckets: 1. Optimization measured in seconds, 2. Optimization measured in milliseconds, 3. Optimization measured in microseconds.
#1 and #2 are worth doing, option #3 is rarely worth doing and most novices will often make performance worse not better when they attempt it.
For #1, start by reducing round trips to the server, set caching headers correctly, compress your JS and CSS files, ... and follow the other advice Yahoo's YSlow plugin offers.
#2 is usually concerned with your database architecture and the queries you are making. Novices often fetch too much data either breadth-wise (columns) or depth-wise (rows). Linq-to-Entities is a great help here for many developers because it defers the actual database work to the latest possible moment when all of the query parameters are known and thus does the least possible amount of work.
Many developers think that caching is the answer on #2 but I advise you to stay well away from trying to implement your own caching scheme. Use what's provided for you in Linq-to-Entities or some other ORM but don't try to roll you own, you are likely to introduce all manner of bugs related to stale data and concurrency issues. And if your queries aren't efficient to begin with you application will not survive a restart under heavy load.
#3 is the hardest of all and the least likely to produce any benefit to the end user. Often it will be detrimental. My advice is to stay well away unless (i) you understand AMD and Intel processor architecture, and (ii) you have a loop that's executed a billion times or more. Microsoft, Intel, AMD and others have spent decades optimizing inefficient code at the CPU and compiler level. Sadly this means that the cleverest algorithm can sometimes be significantly slower than the simplest 'dumb' algorithm. A tight loop doing a dumb linear search in O(n) can perform better than some clever tree search that theoretically runs in O(log(n)) time because the former can fit entirely in on-chip cache and can execute many times faster than the latter. If you are tempted to use a tree or other complex data-structure to 'optimize' access to a small number of items, think again: a simple array might be better and the code will probably be more maintainable and easier to read.
Overall, in terms of optimization, developers need to understand that CPU time is no longer a premium. These days the priorities are A) Network access, B) Disk access, C) Memory access, D) CPU time. If you can use a million CPU cycles to avoid some expensive disk access then it's probably worth it. Too often I see people thinking they are 'optimizing' their code by stuffing a private member variable with some calculated value so they don't have to recalculate it. Guess what, the calculation will take microseconds but the extra RAM you just used to store a million extra private member variables has now caused your application to page more often (both on-chip to off-chip and RAM to disk).
Before you do any optimization you should get a tool like JetBrain's dotTrace, and for memory usage profiling, the Scitech .NET Memory Profiler. These will give you an insight into what needs fixing first and will help you understand where you can trim memory consumption.
Another key rule of optimization is to compare your development (and maintenance costs) for optimized code to the costs of a new server. You could easily spend more trying to get 10% performance gain than it would cost to just get a new quad-core server that will run 20% faster!